
Together with some of the researchers in FINDHR we have authored and submitted an extensive survey on algorithmic hiring. The preprint is available here:
In this multidisciplinary work we bring together different perspectives from computer science, law, and practitioners to extensively survey literature and classify so-called “bias conducive factors,” i.e., factors that contribute to bias in the algorithmic hiring process. These factors span the complete hiring pipeline, and are classified into three main families: institutional biases, individual preferences, and technology blindspots.
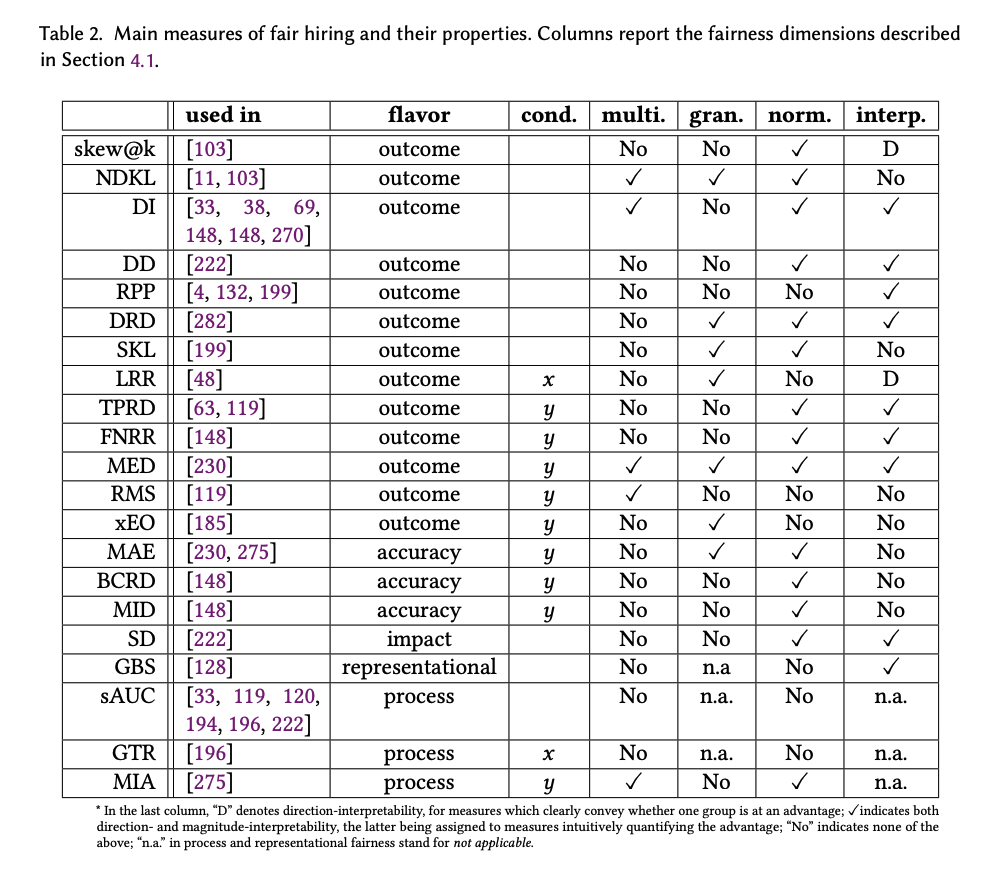
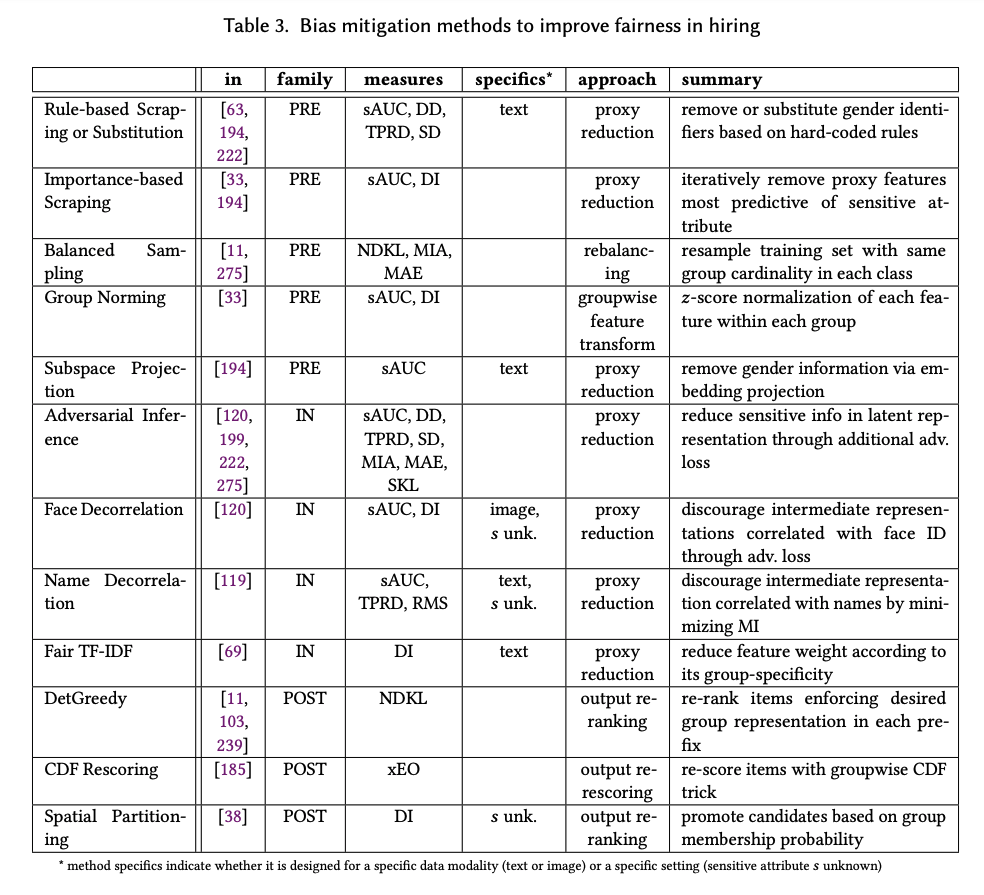
In addition, our paper surveys bias measures (n=21) and bias mitigation strategies (n=12) that have been applied and studied specifically in the context of algorithmic hiring, which we present in unified notation.
Finally, our survey lists datasets, summarizes the relevant legal landscape (w.r.t. regulations and non-discrimination provisions concerning algorithmic hiring in the EU and the US), and shows practical considerations and examples for bias mitigation in practice (which was my main contribution to this paper).
One of my personal main positive takeaways from this paper is around the potential of positive effects that algorithmic components can have in an inherently biased and complex hiring process, i.e.:
One upshot of understanding bias as an inherently intersectional process is that it also offers a way to reduce discrimination. Since the factors that create bias are interrelated and mutually reinforcing, by halting or ameliorating one BCF, we may introduce positive feedback loops on other BCFs. By removing the discriminatory effect of any one factor, we can hope to reduce its influence on the other factors that reinforce each other in a discriminatory way.
All in all, I am very happy and proud to be listed in this monumental work, which surveys a highly complex field and leaves both enough pointers to get started as useful recommendations for future work, grounded in (gaps in) extensive literature.




![[PDF]](https://i0.wp.com/graus.nu/blog/wp-content/plugins/papercite/img/pdf.png?w=840&ssl=1)












{kind=link}
{kind=link}
{kind=link}