Anna Lőrincz‘ UvA MSc. data science thesis “Transfer learning for multilingual vacancy text generation” — which was graded a 9/10 💫 — was recently accepted at the The Second Version of Generation, Evaluation & Metrics (GEM) Workshop 2022 which will be held as part of EMNLP, December 7-11, 2022!
Get the pre-print here:
-
![[PDF]](https://i0.wp.com/graus.nu/blog/wp-content/plugins/papercite/img/pdf.png?w=640&ssl=1)
![[DOI]](https://i0.wp.com/graus.nu/blog/wp-content/plugins/papercite/img/external.png?resize=10%2C10&ssl=1) A. Lőrincz, D. Graus, D. Lavi, and J. L. M. Pereira, “Transfer learning for multilingual vacancy text generation,” in Proceedings of the 2nd workshop on natural language generation, evaluation, and metrics (gem), Abu Dhabi, United Arab Emirates (Hybrid), 2022, p. 207–222.
A. Lőrincz, D. Graus, D. Lavi, and J. L. M. Pereira, “Transfer learning for multilingual vacancy text generation,” in Proceedings of the 2nd workshop on natural language generation, evaluation, and metrics (gem), Abu Dhabi, United Arab Emirates (Hybrid), 2022, p. 207–222.
[Bibtex]@inproceedings{lorincz2022transfer, author = {L{\H{o}}rincz, Anna and Graus, David and Lavi, Dor and Pereira, Jo{\~a}o L. M.}, title = {Transfer learning for multilingual vacancy text generation}, booktitle = "Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM)", month = dec, year = "2022", address = "Abu Dhabi, United Arab Emirates (Hybrid)", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2022.gem-1.18", doi = "10.18653/v1/2022.gem-1.18", pages = "207--222", abstract = "Writing job vacancies is a repetitive and expensive task for humans. This research focuses on automatically generating the benefit sections of vacancies at redacted from job attributes using mT5, the multilingual version of the state-of-the-art T5 transformer trained on general domains to generate texts in multiple languages. While transformers are accurate at generating coherent text, they are sometimes incorrect at including the structured data (the input) in the generated text. Including the input correctly is crucial for vacancy text generation; otherwise, the candidates may get misled. To evaluate how the model includes the input we developed our own domain-specific metrics (input generation accuracy). This was necessary, because Relation Generation, the pre-existing evaluation metric for data-to-text generation uses only string matching, which was not suitable for our dataset (due to the binary field). With the help of the new evaluation method we were able to measure how well the input is included in the generated text separately for different types of inputs (binary, categorical, numeric), offering another contribution to the field. Additionally, we also evaluated how accurate the mT5 model generates the text in the requested language. The results show that mT5 is very accurate at generating the text in the correct language, at including seen categorical inputs and binary values correctly in the generated text. However, mT5 performed worse when generating text from unseen city names or working with numeric inputs. Furthermore, we found that generating additional synthetic training data for the samples with numeric input can increase the input generation accuracy, however this only works when the numbers are integers and only cover a small range.", }
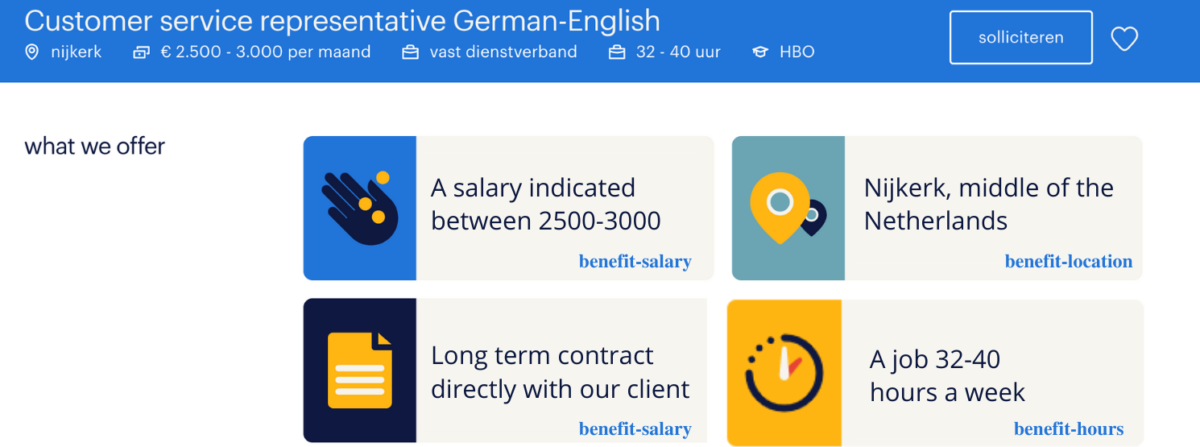
In her work, Anna explores transformer models for data-to-text generation, or more specifically: given structured inputs such as categorical features (e.g., location), real valued features (e.g., salary of hours of work per week), or binary features (e.g., contract type) that represent benefits of vacancy texts, the task is to generate a natural language snippet that expresses said feature.
Anna finds that using transformers greatly increases (vocabulary) variation when compared to template-based models, and needs less human effort. The results were — to me — surprisingly good, another proof that transformers are taking over the world and making traditional NLP methods partly obsolete.
I was very much impressed with this work! But, to show how even transformers are not perfect, yet, I present you with my favorite error from the paper:
input: LOCATION = Zwaag
output: Pal gelegen achter het centraal station Zwaaijdijk!Hope to catch you sometime in Zwaaijdijk!