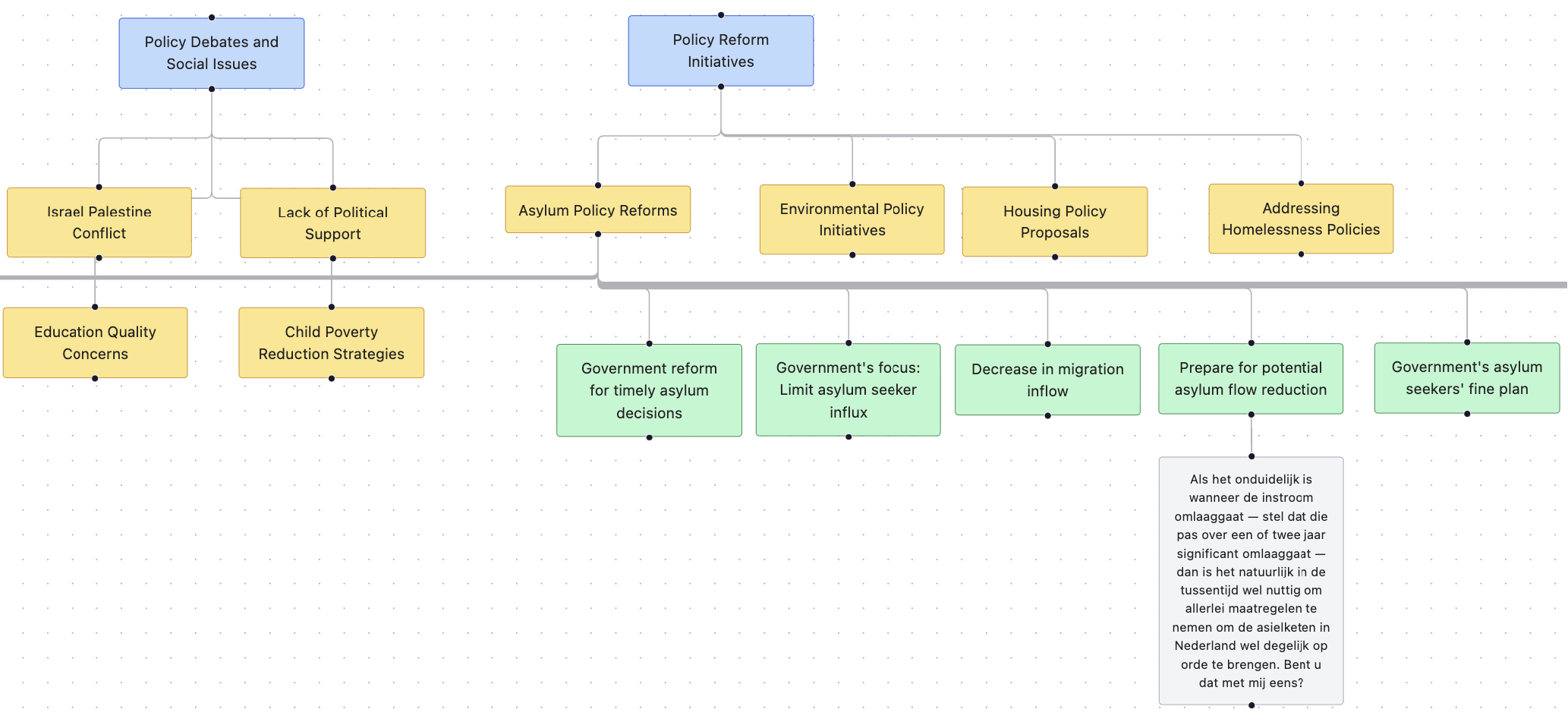
Super happy with the acceptance of our ECIR 2026 Findings paper: “From Quotes to Concepts: Axial Coding of Political Debates with Ensemble LMs“
In this work we apply fine-tuned LLMs for qualitative data analysis (axial coding) of Dutch political debates. This is work led by Angelina Parfenova (Technical University of Munich), who I met at last year’s ECIR in Lucca 🇮🇹. Love it when conference chats turn into papers!
From Quotes to Concepts: Axial Coding of Political Debates with Ensemble LMs
Abstract. We introduce the first method to perform axial coding using large language models (LLMs), transforming raw debate transcripts into concise, hierarchical categories. Axial coding is a qualitative analysis technique that organizes codes (labels) representing text into broader categories, enhancing document understanding and analysis. Starting with sentence-level labels (open codes) generated by an LLM ensemble with a moderator, we introduce an axial coding step that groups these codes into higher-order categories. We compare two strategies: (i) clustering (code + utterance) embeddings using density-based and partitioning algorithms followed by LLM labeling, and (ii) direct LLM-based grouping of codes and utterances into categories. We apply our method to Dutch parliamentary debates, converting lengthy transcripts into compact, hierarchically structured codes and categories. We evaluate our method using extrinsic metrics aligned with human-assigned topic labels (ROUGE-L, cosine, BERTScore), and intrinsic metrics describing code groups (coverage, brevity, coherence, novelty, JSD divergence). Our results reveal a trade-off: density-based clustering achieves high coverage and strong cluster alignment, while direct LLM grouping results in higher fine-grained alignment, but lower coverage (∼20%). Overall, clustering maximizes coverage and structural separation, whereas LLM grouping produces more concise, interpretable, and semantically aligned categories. To support future research, we publicly release the full dataset of utterances and codes, enabling reproducibility and comparative studies.
This is also my first full (and OpenGov-themed) co-authored paper since rejoining academia and running the OpenGov Lab!
Stay tuned for the preprint.