
Ik heb een iBestuur-hattrick! En stond de afgelopen twee dagen drie keer op iBestuur, om uiteenlopende redenen. Voor wie het overzicht kwijt is, een korte rondgang met links naar het origineel.
2 juni: Audio uit raadsvergaderingen levert een schat aan info op (crosspost van Binnenlands Bestuur)
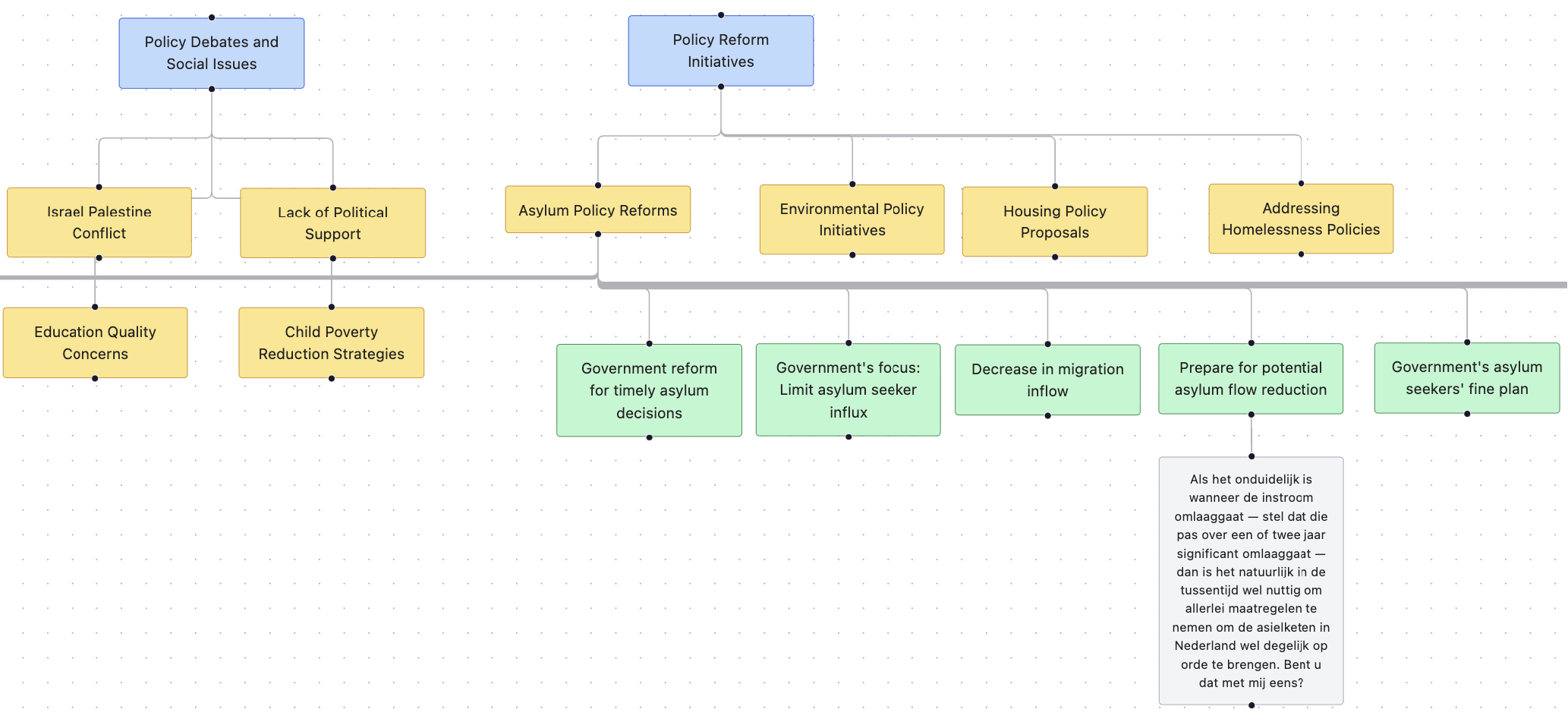
Over hoe we werken met lange, ontoegankelijke audio-opnames van raadsvergaderingen, door ze op te knippen in doorzoekbare ‘nuggets, of de audiotranscripten samen te vatten met LLMs. Wat laten die dan weg? In ieder geval procedurele zaken, maar misschien ook inhoudelijke onderwerpen. Stay tuned!
3 juni: AI en Open Overheid: lessen van de internationale wetenschap
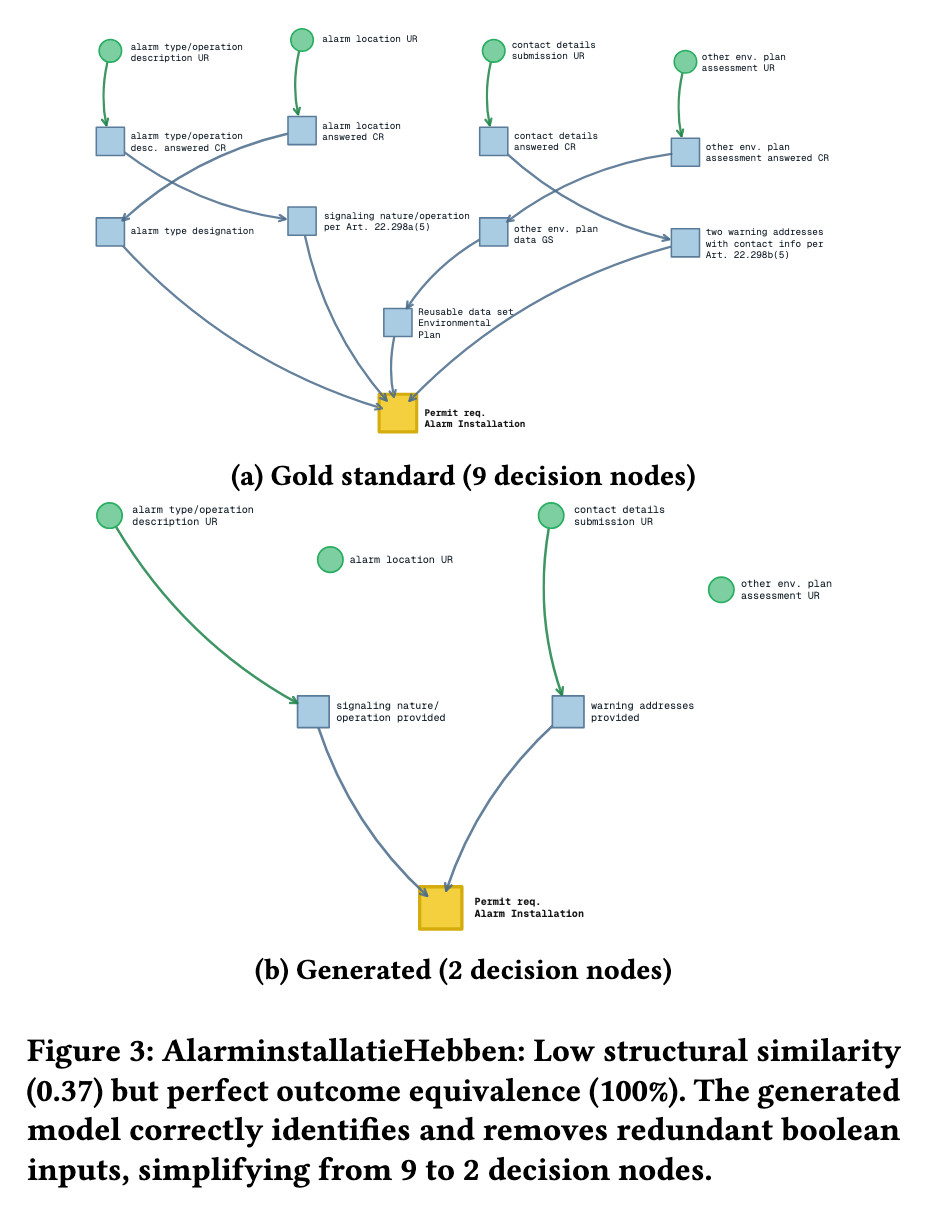
Mijn eigen stuk: een vogelvlucht door het onderzoek dat op 8 juni in Singapore wordt gepresenteerd op onze AI & Open Government workshop. Ik heb hier geprobeerd de ‘praktische inzichten’ op te sommen in gewone mensentaal, voor bestuurders. Die inzichten? Met publiek beschikbare en open-source modellen, slim gecombineerd, kom je al een heel eind met AI inzetten voor de Woo.
3 juni: Vijf jaar later: hoe is het met de Woo?
Het verslag van de vijfde Woo-ontbijtsessie, waar ik aan tafel zat met staatssecretaris Eric van der Burg, Ingeborg Harmsen en Onno Eric Blom. Mijn punt: voor informatiehuishouding bij de overheid kunnen we best wat minder gestructureerd zijn, en meer leunen op bewezen zoektechnologie.
Nu is het vast een goed moment voor iBestuur en ik om even wat afstand van elkaar te nemen. Allicht tot volgend jaar!

![[PDF]](https://i0.wp.com/graus.nu/blog/wp-content/plugins/papercite/img/pdf.png?w=640&ssl=1)












{kind=link}