In our paper “Recipient recommendation in enterprises using communication graphs and email content“ we study email traffic, by looking into recipient recommendation, or: given an email without recipients, can we predict to whom it should be sent? Successfully predicting this helps in understanding the underlying mechanics and structure of an email network. To model this prediction task we consider the email traffic as a network, or graph, where each unique email account (user) corresponds to a node, and edges correspond to emails sent between users (see e.g., Telecommunications network on Wikipedia).

Google does recipient recommendation (in Gmail) by considering a user’s so-called egonetwork, i.e., a single user’s previously sent and received emails. When you frequently email Alan and Bob jointly, Gmail (might) suggest you to include Alan when you compose a new message to Bob. This approach only considers previous interactions between you and others (restricted to the egonetwork), and ignores signals such as the content of an email. This means that Gmail can only start recommending users once you’ve addressed at least one recipient (technically, this isn’t recipient recommendation, but rather “CC prediction”).
We decided to see what we can do if we consider all information available in the network, i.e., both the full communication graph (beyond the user’s ego-network), and the content of all emails present in the network (intuition: if you write a message with personal topics, the intended recipient is more likely to be a friend than a coworker). In short, this comes down to combining;
- Social network analysis (SNA): to estimate how “close” two emailers are in the network. Hypothesizing that the closer people are, the more likely they mail. And;
- Language modeling (LM), to estimate how strongly an email is associated to a recipient. We estimate this by generating personal language models, for each user in the network. A language model is a statistical model that estimates for a set of documents (in our case, a user’s sent and received emails) the probability of observing a word: words that you frequently use will receive high probabilities, and words that you never use receive low probabilities. In effect, this language model corresponds to a user’s “language profile”. Representing each user through language models (that represent their communication) allows us to compare users, but also do more fancy stuff which I’ll get into later.
We model the task of recommending recipients as that of ranking users. Or, given a sender (you) and an email (the email you wrote) the task is to rank highest those users in the network that are most likely to receive your email. This ranking should happen in a streaming setting, where we update all models (language and network) for each new email that is being sent (so that we do not use “future emails” in predicting the recipients). This means that the network and language models change over time, and adapt to changes in language use, topics being discussed, but also the ‘distance’ between users in the network.
Generative model
We use a generative model to rank recipients, by estimating the probability of observing a recipient (R), given an email (E) and sender (S);

If you don’t get this, don’t worry, in human language this reads as: the probability (P) of observing recipient R, given sender S and email E. We compute this probability for each pair of users in the network, and rank the resulting probabilities to find the most likely sender & recipient pair.
In this ranking function, we consider three components to estimate this probability (see our paper for how we use Bayes’ Theorem to end up with this final ranking function). One corresponds to the email content, the other two correspond to the SNA properties;

Email content
The first component (
- Each user’s incoming email-LM, modeled by taking all the emails that are sent to the user. This corresponds to “how people talk to the user”
- Each user’s outgoing email-LM, modeled by taking all the emails that the user has sent. This corresponds to “how the user talks to others”
- Each user’s joint (incoming+outgoing) LM, which is the combination of the above two.
Finally, using these different language models, we model interpersonal language models, or the communication between two users (taking all email traffic between user A and user B). See the picture below for an illustration of these different language models.

Using this method of modeling email communications can be applied for more cool things that we didn’t fully explore for this paper, e.g., finding users that use significantly different language from the rest, by comparing how much a user’s incoming, outgoing or joint LM differs from the corpus LM. Or comparing the interpersonal LM’s that are associated with a single user, to identify a significantly different one (imagine comparing your emails with coworkers to those with your boyfriend/girlfriend/spouse). Future work! (?)
Communication graph
The second component (
The third and final component (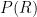
Experiments
We use the notorious Enron email corpus to find the best methods to estimate our components. Then, we use a very new, and soon-to-be-released Avocado corpus to evaluate our model. In brief, I won’t go into detail of our experiments (see the paper for those!), but suffice to say that we compare the effectiveness of the email content (LM) component and the social network analysis (SNA) components. There are several findings worth mentioning:
- Combining both components (content & social network) is favorable.
- For highly active users (i.e., those that send LOTS of emails) the LM approach does comparatively worse. We argue that the reason is that highly active users have a larger number of highly ranked candidate recipients (because there are more highly scoring interpersonal LMs), making it more difficult to pick the right one.
- As time progresses, the SNA component does comparatively worse. We argue that this is because the network “settles in”; consider a scenario where two users mail actively with each other for months, but then one of the two users disappears from the network (e.g., is fired from/leaves the enterprise), in such a case, our SNA component will continue to highly rank this user.
- The LM component improves as time progresses (as it has more data to work with).
The solution for the two ‘issues’ (2nd and 3rd bullet) is to incorporate time in our models, e.g. by introducing a decay in the language modeling (older emails become less important), and edge weights in the SNA components (older interactions count less than recent ones).
Got it? Read the paper for the full story! (PDF here)
One thought on “Understanding Email Traffic: Social Network Analysis Meets Language Modeling”