
Shanghai Back Alley

Understanding Email Traffic: Social Network Analysis Meets Language Modeling
In our paper “Recipient recommendation in enterprises using communication graphs and email content“ we study email traffic, by looking into recipient recommendation, or: given an email without recipients, can we predict to whom it should be sent? Successfully predicting this helps in understanding the underlying mechanics and structure of an email network. To model this prediction task we consider the email traffic as a network, or graph, where each unique email account (user) corresponds to a node, and edges correspond to emails sent between users (see e.g., Telecommunications network on Wikipedia).

Google does recipient recommendation (in Gmail) by considering a user’s so-called egonetwork, i.e., a single user’s previously sent and received emails. When you frequently email Alan and Bob jointly, Gmail (might) suggest you to include Alan when you compose a new message to Bob. This approach only considers previous interactions between you and others (restricted to the egonetwork), and ignores signals such as the content of an email. This means that Gmail can only start recommending users once you’ve addressed at least one recipient (technically, this isn’t recipient recommendation, but rather “CC prediction”).
We decided to see what we can do if we consider all information available in the network, i.e., both the full communication graph (beyond the user’s ego-network), and the content of all emails present in the network (intuition: if you write a message with personal topics, the intended recipient is more likely to be a friend than a coworker). In short, this comes down to combining;
- Social network analysis (SNA): to estimate how “close” two emailers are in the network. Hypothesizing that the closer people are, the more likely they mail. And;
- Language modeling (LM), to estimate how strongly an email is associated to a recipient. We estimate this by generating personal language models, for each user in the network. A language model is a statistical model that estimates for a set of documents (in our case, a user’s sent and received emails) the probability of observing a word: words that you frequently use will receive high probabilities, and words that you never use receive low probabilities. In effect, this language model corresponds to a user’s “language profile”. Representing each user through language models (that represent their communication) allows us to compare users, but also do more fancy stuff which I’ll get into later.
We model the task of recommending recipients as that of ranking users. Or, given a sender (you) and an email (the email you wrote) the task is to rank highest those users in the network that are most likely to receive your email. This ranking should happen in a streaming setting, where we update all models (language and network) for each new email that is being sent (so that we do not use “future emails” in predicting the recipients). This means that the network and language models change over time, and adapt to changes in language use, topics being discussed, but also the ‘distance’ between users in the network.
Generative model
We use a generative model to rank recipients, by estimating the probability of observing a recipient (R), given an email (E) and sender (S);

If you don’t get this, don’t worry, in human language this reads as: the probability (P) of observing recipient R, given sender S and email E. We compute this probability for each pair of users in the network, and rank the resulting probabilities to find the most likely sender & recipient pair.
In this ranking function, we consider three components to estimate this probability (see our paper for how we use Bayes’ Theorem to end up with this final ranking function). One corresponds to the email content, the other two correspond to the SNA properties;

Email content
The first component (
- Each user’s incoming email-LM, modeled by taking all the emails that are sent to the user. This corresponds to “how people talk to the user”
- Each user’s outgoing email-LM, modeled by taking all the emails that the user has sent. This corresponds to “how the user talks to others”
- Each user’s joint (incoming+outgoing) LM, which is the combination of the above two.
Finally, using these different language models, we model interpersonal language models, or the communication between two users (taking all email traffic between user A and user B). See the picture below for an illustration of these different language models.

Using this method of modeling email communications can be applied for more cool things that we didn’t fully explore for this paper, e.g., finding users that use significantly different language from the rest, by comparing how much a user’s incoming, outgoing or joint LM differs from the corpus LM. Or comparing the interpersonal LM’s that are associated with a single user, to identify a significantly different one (imagine comparing your emails with coworkers to those with your boyfriend/girlfriend/spouse). Future work! (?)
Communication graph
The second component (
The third and final component (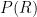
Experiments
We use the notorious Enron email corpus to find the best methods to estimate our components. Then, we use a very new, and soon-to-be-released Avocado corpus to evaluate our model. In brief, I won’t go into detail of our experiments (see the paper for those!), but suffice to say that we compare the effectiveness of the email content (LM) component and the social network analysis (SNA) components. There are several findings worth mentioning:
- Combining both components (content & social network) is favorable.
- For highly active users (i.e., those that send LOTS of emails) the LM approach does comparatively worse. We argue that the reason is that highly active users have a larger number of highly ranked candidate recipients (because there are more highly scoring interpersonal LMs), making it more difficult to pick the right one.
- As time progresses, the SNA component does comparatively worse. We argue that this is because the network “settles in”; consider a scenario where two users mail actively with each other for months, but then one of the two users disappears from the network (e.g., is fired from/leaves the enterprise), in such a case, our SNA component will continue to highly rank this user.
- The LM component improves as time progresses (as it has more data to work with).
The solution for the two ‘issues’ (2nd and 3rd bullet) is to incorporate time in our models, e.g. by introducing a decay in the language modeling (older emails become less important), and edge weights in the SNA components (older interactions count less than recent ones).
Got it? Read the paper for the full story! (PDF here)
ECIR 2014 Press Release

Together with the persvoorlichting of the UvA we wrote a press release announcing our upcoming conference, check it out below.
English (translated through UvA) follows Dutch (original).
Nieuwe inzichten en ontwikkelingen in zoekmachinetechnologie (link)
European Conference on Information Retrieval
Wat kan een zoekmachine – op basis van wat je zoekt en waar je op klikt – afleiden over je identiteit en gedrag? Hoe kan ‘gamification’ ingezet worden om zoekmachines te verbeteren? En welke rol speelt het verzamelen en toegankelijk maken van verschillende datastromen in de stad van de toekomst? Deze en andere vragen worden beantwoord tijdens de 36e ‘European Conference on Information Retrieval’ (ECIR ‘14).
De conferentie, die dit jaar plaatsvindt van 13 tot en met 16 april in Amsterdam, brengt de internationale top van onderzoekers op het terrein van information retrieval (zoekmachinetechnologie) samen. Aan bod komen onderwerpen als personalisatie van zoekresultaten,recommender systems (aanbevelingssystemen), datamining in sociale media, en eCommerce en product search. Eugene Agichtein (Emory University, VS) opent ECIR ’14 met een keynote waarin hij ingaat op het afleiden van intenties en gedrag van internetgebruikers uit hun interacties met zoekmachines.
Technologische innovaties
Toegang tot (big) data en kostbare infrastructuren worden steeds belangrijker in de information retrieval. In een paneldiscussie belichten prominenten uit zowel het bedrijfsleven als de wetenschap de huidige stand van zaken en toekomstige ontwikkelingen in het onderzoeksveld. De industry day op woensdag 16 april wordt geopend met een keynote door Gilad Mishne (hoofd van het zoekteam van Twitter) over real-time zoeken op Twitter. Vervolgens presenteren (inter)nationale bedrijven, waaronder Yahoo! en eBay, hun laatste technologische innovaties.
Nederland is één van de meest vooraanstaande landen als het gaat om wetenschappelijk onderzoek in de information retrieval. De organisatie van ECIR ‘14 ligt in handen van het Intelligent Systems Lab Amsterdam (ISLA) van de Universiteit van Amsterdam, met ondersteuning van onder meer zoekgiganten als Microsoft, Yahoo!, Yandex en Google.
Locatie
Hotel Casa 400
Eerste Ringdijkstraat 4
1097 BC Amsterdam
New insights and developments in search engine technology (link)
European Conference on Information Retrieval
What can a search engine deduce about your identity and habits based on the topics you search and select? How can gamification be used to improve search engines? And what role will the collection and provision of access to diverse data flows play in the city of the future? These are just a few of the questions to be addressed during the 36th European Conference on Information Retrieval (ECIR 14).
Set to take place on 13-16 April, the conference will bring international frontrunners in the field of information retrieval (search engine technology) together in Amsterdam. Topics to be covered include: the personalisation of search results, recommender systems, product search and data mining in social media and eCommerce. Opening the ECIR 14 will be Eugene Agichtein (Emory University, USA) with a keynote address explaining how the intentions and habits of Internet users can be deduced from their search engine interactions.
Technological innovations
Access to big data and high-cost infrastructures is becoming an increasingly important factor in information retrieval. In a panel discussion, leading names in business and science will shed light on the current state of play and what research in this field has in store. The special industry day on Wednesday, 16 April will open with a keynote address by Gilad Mishne (head of the Twitter search team) on real-time search on Twitter. This will be followed by presentations by various Dutch and international companies, including Yahoo! and eBay, about their own latest technologies.
The Netherlands is one of the pioneers in worldwide scientific research into information retrieval. The ECIR 14 is being organised by the University of Amsterdam’s Intelligent Systems Lab Amsterdam (ISLA) with support from search engine giants such as Microsoft, Yahoo!, Yandex and Google.
Time and location
Time: 09:00 Sunday, 13 April – 17:00 Wednesday, 16 April
Location: Hotel Casa 400, Eerste Ringdijkstraat 4, Amsterdam
Manhattan

Union Station, Washington DC

Union Station through the eye of a fish on land

Information Retrieval at LegalTech 2014

Thanks to the kind lady at the registration desk I had the unexpected honor of representing the beautiful former Carribean country of the Netherlands Antilles at LegalTech 2014, the self-proclaimed largest and most important legal technology event of the year.

LegalTech is an “industry conference” where attorneys, lawyers, and IT people meet up and discuss the current and future state of law and IT. Product vendors show their software and tools aimed at making the life of the modern-day attorney easier. As I work on semantic search in eDiscovery, my reasons to attend (being generously invited by Jason Baron) were;
- To get a better overview and understanding of eDiscovery (in the US).
- To see what people consider the ‘future’ or important topics within eDiscovery.
- To understand what the current state of the art is in tools and applications.
- (To plug semantic search)
Indeed, in summary, to retrieve information! (As an IR researcher does). The conference included keynotes, conference tracks, panel discussions and a huge exhibitor show where over 100 vendors of eDiscovery-related software present their products. All this fits on just three floors of the beautiful Hilton Midtown Hotel in the middle of New York.
To get a feel of the topics and themes, tracks titles included a.o. eDiscovery, Transforming eDiscovery, Big Data, Information Governance, Advanced IT, Technology in Practice, Technology and Trends Transforming the Legal World, Corporate Legal IT.
Me@LegalTech
LegalTech is a playground for attorneys and lawyers, not so much PhD students who work on information extraction and semantic search. Needless to say I was far from the typical attendant (possibly the most atypical). But LegalTech proved to be an informative and valuable crash course in eDiscovery for me (I think I can tick the boxes of all 4 of the aforementioned reasons for attending).

The keynotes allowed me to get a better understanding of eDiscovery (a.o., through hearing some of the founders of the eDiscovery world), the panel discussions were very useful in getting an understanding of the open problems, challenges and future directions, and finally the trade show allowed me to get a very complete overview of what is being built and used right now in terms of eDiscovery-supporting software.
I had varying success of talking to vendors about the stuff I was interested in: technology and algorithms behind tools, and choices for including or excluding certain features and functionalities. More frequently than not would an innocently nerdy question from my part be turned around into a software salespitch. To be fair, these people were here to sell, or at least show, so this is hardly unexpected.
The tracks: my observations
During the different tracks and panel discussions I attended, I noticed a couple of things. This is by no means a complete overview of the current things that matter in eDiscovery, but just a personal report of the things I found interesting or noteworthy;
Some of the “open door” recurring themes revolved around the “man vs machine”-debate, trust in algorithms, balance in computer assisted review vs manual review, the intricacies of algorithm performance measurement, and where Moore’s law will bring the law world in 5-10 years. Highly relevant issues for attorneys, lawyers and eDiscovery vendors, but things that I take for granted, and consider the starting point (default win for algorithms!). However, it seems like this is a debate that is not yet settled in this domain, it also seems that while everyone accepts computer assisted review as the unavoidable future, it seems still unclear what this unavoidable future exactly will look like.
On multiple occasions I heard video and image retrieval being mentioned as important future directions for eDiscovery (good news for some colleagues at the University of Amsterdam down the hall). Also, the challenge of privacy and data ownership in a mobile world, where enterprise and personal data are mixed and spread out across iPads, smartphones, laptops and clouds, were identified as major future hurdles.
Finally, in the session titled “Have we Reached a “John Henry” Moment in Evidentiary Search?” the panelists (which included Jason Baron and Ralph Losey) touched upon using eDiscovery tools and algorithms for information governance. Currently, methods are being developed to detect, reconstruct, classify or find events of interest: after the fact. Couldn’t these be used in a predictive setting, instead of a retro-spective one; learning to predict bad stuff before it happens. Interesting stuff.
The tradeshow: metadata-heavy

What I noticed particularly at the trade show was that there was a large overlap both in tools’ functionality and features and their looks and designs. But what I found more striking is the heavy focus on metadata. The tools typically use metadata such as timestamps, authors, and document types to allow users to drill down through a dataset, filtering for time periods, keywords, authors, or a combination of all of these.
Visualizations a plenty, with the most frequent ones being Google Ngrams-ish keyword histograms, and networks (graphs) of interactions between people. What was shocking for an IR/IE person like myself is that typically, once a user is done drilling down to a subset of document, he is designated to prehistoric keyword search to explore and understand the content of the set of documents. Oh no!
But for someone who’s spending 4 years of his life to enabling semantic search in this domain this isn’t worrying, but rather promising! After talking to vendors I learned that plenty of them are interested in these kind of features and functionalities, so there is definitely room for innovation here. (However to be fair, whether the target users agree might be another question).
Highlights
Anyway, this ‘metadata heaviness’ is obviously a gross oversimplification and generalization, and there were definitely some interesting companies that stood out for me. Here’s a small, incomplete, and biased summary;
- I had some nice talks with the folks at CatalystSecure, who’s senior applied research scientist and former IR academic (dr. Jeremy Pickens) was the ideal companion to be unashamedly nerdy with, talking about classification performance metrics, challenges in evaluating the “whole package” of the eDiscovery process, and awesome datasets.
- RedOwl Analytics do some very impressive stuff with behavioural analytics, where they collect statistics for each ‘author’ in their data (such as number of emails sent and received, ‘time to respond’, number of times cc’ed), to get an ‘average baseline’ of a single dataset (enterprise), that they can use to recognize individuals who deviate from this average. The impressive part was that they were then able to map these deviations to behavioural traits (such as ‘probability of an employee leaving a company’, or on the other side of the spectrum identifying the ‘top employees’ that otherwise remain under the radar). How that works under the hood remains a mystery for me, but the type of questions they were able to answer in the demo were impressive.
- Recommind‘s CORE platform seems to rely heavily on topic modeling, and was able to infer topics from datasets. In doing so, Recommind shows we can indeed move beyond keyword search in a real product (and outside of academic papers 😉 ). This doesn’t come as a surprise, seeing that Recommind’s CTO dr. Jan Puzicha is of probabilistic latent semantic indexing (/analysis) fame.
What’s next?
As I hinted at before, I’m missing some more content-heavy functionalities, e.g., (temporal) entity and relation extraction, identity normalization, maybe (multi document) summarization? Conveniently, this is exactly what me and my group are working on! I suppose the eDiscovery world just doesn’t know what they’re missing, yet ;-).
New York at night

New York

Downtown DC

Curvy Alley

Sackler and Freer Gallery of Art

Generating Pseudo-ground Truth for Predicting New Concepts in Social Streams accepted at ECIR2014
Our paper “Generating Pseudo-ground Truth for Predicting New Concepts in Social Streams” with Manos Tsagkias, Lars Buitinck, and Maarten de Rijke got accepted as a full paper to ECIR 2014! See a preprint here:
-
![[PDF]](https://i0.wp.com/graus.nu/blog/wp-content/plugins/papercite/img/pdf.png?w=840&ssl=1)
![[DOI]](https://i0.wp.com/graus.nu/blog/wp-content/plugins/papercite/img/external.png?resize=10%2C10&ssl=1) D. Graus, M. Tsagkias, L. Buitinck, and M. de Rijke, “Generating pseudo-ground truth for predicting new concepts in social streams,” in Advances in information retrieval, Cham, 2014, p. 286–298.
D. Graus, M. Tsagkias, L. Buitinck, and M. de Rijke, “Generating pseudo-ground truth for predicting new concepts in social streams,” in Advances in information retrieval, Cham, 2014, p. 286–298.
[Bibtex]@inproceedings{graus2014generating, author={Graus, David and Tsagkias, Manos and Buitinck, Lars and de Rijke, Maarten}, title={Generating Pseudo-ground Truth for Predicting New Concepts in Social Streams}, booktitle={Advances in Information Retrieval}, year={2014}, publisher={Springer International Publishing}, address={Cham}, pages={286--298}, url={https://doi.org/10.1007/978-3-319-06028-6_24}, doi={10.1007/978-3-319-06028-6_24}, series = {ECIR '14} }
Layman explanation
This blog post is intended as a high level overview of what we did. Remember my last post on entity linking? In this paper we want to do entity linking on entities that are not (yet) on Wikipedia, or:
Recognizing (finding) and classifying (determining their type: persons, locations or organizations) unknown (not in the knowledge base) entities on Twitter (this is where we want to find them)
These entities might be unknown because they are newly surfacing (e.g. a new popstar that breaks through), or because they are so-called ‘long tail’ entities (i.e. very infrequently occurring entities).
Method
To detect these entities, we generate training data, to train a supervised named-entity recognizer and classifier (NERC). Training data is hard to come by: it is expensive to have people manually label Tweets, and you need enough of these labels to make it work. We automate this processing by using the output of an entity linker to label Tweets. The advantage is this is very cheap and easy to create a large set of training data. The disadvantage is that there might be more noise: wrong labels, or bad tweets that do not contain enough information to learn patterns to recognize the types of entities we are looking for.
To address this latter obstacle, we apply several methods to filter Tweets which we deem ‘nice’. One of these methods involves scoring Tweets based on their noise. We applied very simple features to determine this ‘noise-level’ of a tweet; amongst others how many mentions (@’s), hashtags (#’s) and URLs it contains, but also the ratio between upper-case to lower-case letters, the average word length, the tweet’s length, etc. An example for this Twitter-noise-score is below (these are Tweets from the TREC 2011 Microblog corpus we used):
Top 5 quality Tweets
- Watching the History channel, Hitler’s Family. Hitler hid his true family heritage, while others had to measure up to Aryan purity.
- When you sense yourself becoming negative, stop and consider what it would mean to apply that negative energy in the opposite direction.
- So. After school tomorrow, french revision class. Tuesday, Drama rehearsal and then at 8, cricket training. Wednesday, Drama. Thursday … (c)
- These late spectacles were about as representative of the real West as porn movies are of the pizza delivery business Que LOL
- Sudan’s split and emergence of an independent nation has politico-strategic significance. No African watcher should ignore this.
Top 5 noisy Tweets
- Toni Braxton ~ He Wasnt Man Enough for Me _HASHTAG_ _HASHTAG_? _URL_ RT _Mention_
- tell me what u think The GetMore Girls, Part One _URL_
- this girl better not go off on me rt
- you done know its funky! — Bill Withers “Kissing My Love” _URL_ via _Mention_
- This is great: _URL_ via _URL_
In addition, we filter Tweets based on the confidence score of the entity linker, so as not to include Tweets that contain unlikely labels.
Experimental Setup
It is difficult to measure how well we do in finding entities that do not exist on Wikipedia, since we need some sort of ground truth to determine whether we did well or not. As we cannot manually check for 80.000 Tweets whether the identified entities are in or out of Wikipedia, we take a slightly theoretical approach.
If I were to put it in a picture (and I did, conveniently), it’d look like this:

In brief, we take small ‘samples’ of Wikipedia: one such sample represent the “present KB”; the initial state of the KB. The samples are created by removing out X% of the Wikipedia pages (from 10% to 90% in steps of 10). We then label Tweets using the full KB (100%) to create the ground truth: this full KB represents the “future KB”. Our “present KB” then labels the Tweets it knows, and uses the Tweets it cannot link as sources for new entities. If then the NERC (trained on the Tweets labeled by the present KB) manages to identify entities in the set of “unlinkable” Tweets, we can compare the predictions to the ground truth, and measure performance.
Results & Findings
We report on standard metrics: Precision & Recall, on two levels: entity and mention level. However, I won’t go into any details here, because I encourage you to read the results and findings in the paper.
Media
Several Dutch media have picked up our work:
Original press release:
- English: New method supplements Wikipedia with Twitter topics
- Dutch: Nieuwe methode vult Wikipedia aan met onderwerpen Twitter
Press coverage:
- Tweakers.net: Nieuw algoritme vult Wikipedia aan op basis van Twitterberichten
- DeMorgen.be: Nieuw algoritme vult Wikipedia aan op basis van tweets
- Emerce: Nederlands algoritme reikt nieuwe Wikipedia onderwerpen aan
- Twittermania: Wordt Wikipedia straks gevuld via tweets?
- Z24: Algoritme gebruikt Twitter om nieuwe Wikipedia-artikelen te voorspellen
Slides
Slides of my talk at #ECIR2014 are now up on Slideshare;
What to post next?
Hello, an awesome day to all of you. Adam is offering me a guestpost. What to pick, what to pick?
Hey!
Hope you are having an awesome day!
I would like to express my interest to submit a compelling guest post.
All our articles are visually appealing & written with care and love and detailed research.
To get a feel for how I write, see the below posts I did for some quite authoritative sites:
– http://www.www.some_random_website.com/2013/09/17/apple-introduces-fresh-iphone-models/
– http://www.some_random_website.com/social-media/2013/09/17/how-to-optimize-your-landing-pages-for-facebook-traffic/
– http://www.some_random_website.com/internet-marketing/url-shorteners.htmlHere are the articles I have available as of now.
https://docs.google.com/spreadsheet/ccc?key=0AtEuXUDUUU4VdEl5U0NHajI5VEpma19IekdoNmN6U3c#gid=0
??? This sheet is updated daily at 8am so you can check back anytime and request more articles ANYTIME ???
Which one would you be most interested in?
Regards,
Adam Prattler
Disclaimer & Important rules:
All content remains the sole property of Adam’s website and is only lend to you on condition of our link being placed in either the author bio or body.
My reply:
Thanks for expressing your interest in submitting a compelling guest post. It has been duly noted!
You have an awesome day too!
David
SEO just got more scary.